An F1 car is the wrong tool for a milk run. It can be fast, expensive, and impressive while still being a terrible default.
Many AI budgets are built exactly that way: premium model first, task second.
Model labs are vendors. The best ones ship extraordinary products, but the commercial pull is simple: more work through premium paths, bigger prompts, deeper reasoning, more tool loops, more usage.
Your objective with AI is different from theirs: improve the bottom line by making workflows faster, cheaper, more accurate, and easier to review. That means optimizing by use case: speed where speed matters, intelligence where judgment matters, lower-cost routes where work is routine.
That is the mismatch: the lab wins when work moves upmarket. You win when work passes your experts' criteria at the right cost.
The Meter Is the Incentive
Old SaaS was legible: seats multiplied by price.
Agentic AI is harder to read because it bills by behavior: context, hidden reasoning, tool calls, retries, file reads, and default model choice. OpenAI's pricing shows the spread: gpt-5.5 is $5 per million input tokens and $30 per million output tokens, while gpt-5.5-pro is $30 and $180. Hidden reasoning tokens are billed too.
Anthropic's pricing has the same shape. Claude Opus 4.8 is $5 per million input tokens and $25 per million output tokens, while Sonnet and Haiku are cheaper. Tool schemas, tool results, system prompts, and multi-turn loops add tokens before anyone sees the answer.
The rate card is only the visible part. Anthropic says Opus 4.7 can turn the same input into roughly 1.0-1.35x more tokens. Higher effort can also produce more output tokens in later agentic turns.
That puts the tokenizer in the IPO story. Axios reported on June 1, 2026 that Anthropic filed for its IPO, then warned the next day that customer cost backlash could weaken revenue as Anthropic prepares to go public. Can you blame a company heading toward public markets for caring about the meter? Of course not. Just do not let its meter become your ROI model. In a token-metered business, more billable tokens can lift revenue before adoption changes.
Carry one metric through the budget conversation: accepted work per dollar, with latency and error rate attached. On a hard investigation, gpt-5.5-pro may matter. For one polite email, does the Pro model change the outcome?
More work is becoming agentic. Token growth is expected; the question is what you got for the tokens.
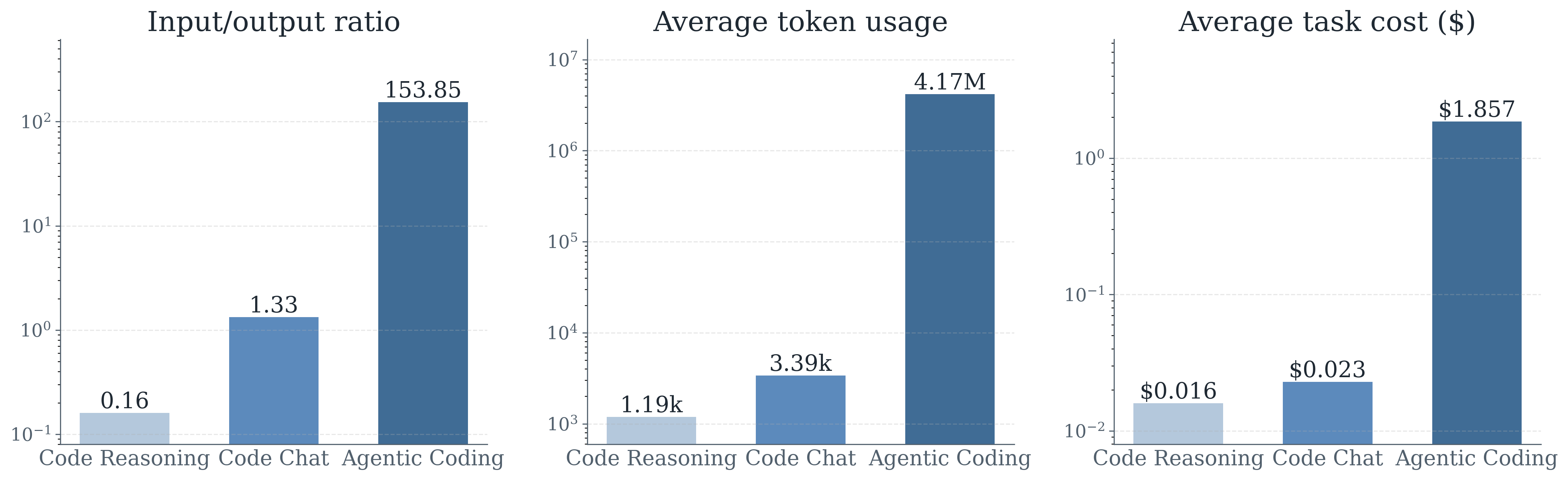
Bai et al. quantify that denominator: in their paper, agentic coding used roughly 1,231x more tokens and 81x more dollars per task than code chat. The lesson is priced routes: task budget, latency target, accuracy bar, review standard. A loop that closes a production issue may be cheap. A loop that drafts a routine email feeds the meter.
Usage Is Not ROI
The invoice problem starts when too much work goes to the strongest model or longest agentic loop before the company defines purpose, quality, latency, and cost. TechCrunch reported that Uber put a $1,500 monthly cap per employee and per agentic coding tool after burning through its annual AI budget in four months. Axios calls the broader pattern "AI sticker shock".
Usage is easy to celebrate until finance closes the books. ROI starts when activity becomes accepted output.
The 2026 enterprise AI survey from a16z found average enterprise LLM spend had reached about $7 million. Its use-case breakdown is the sharper signal: enterprises already choose different model families for chat, software development, support, data analysis, and automation.
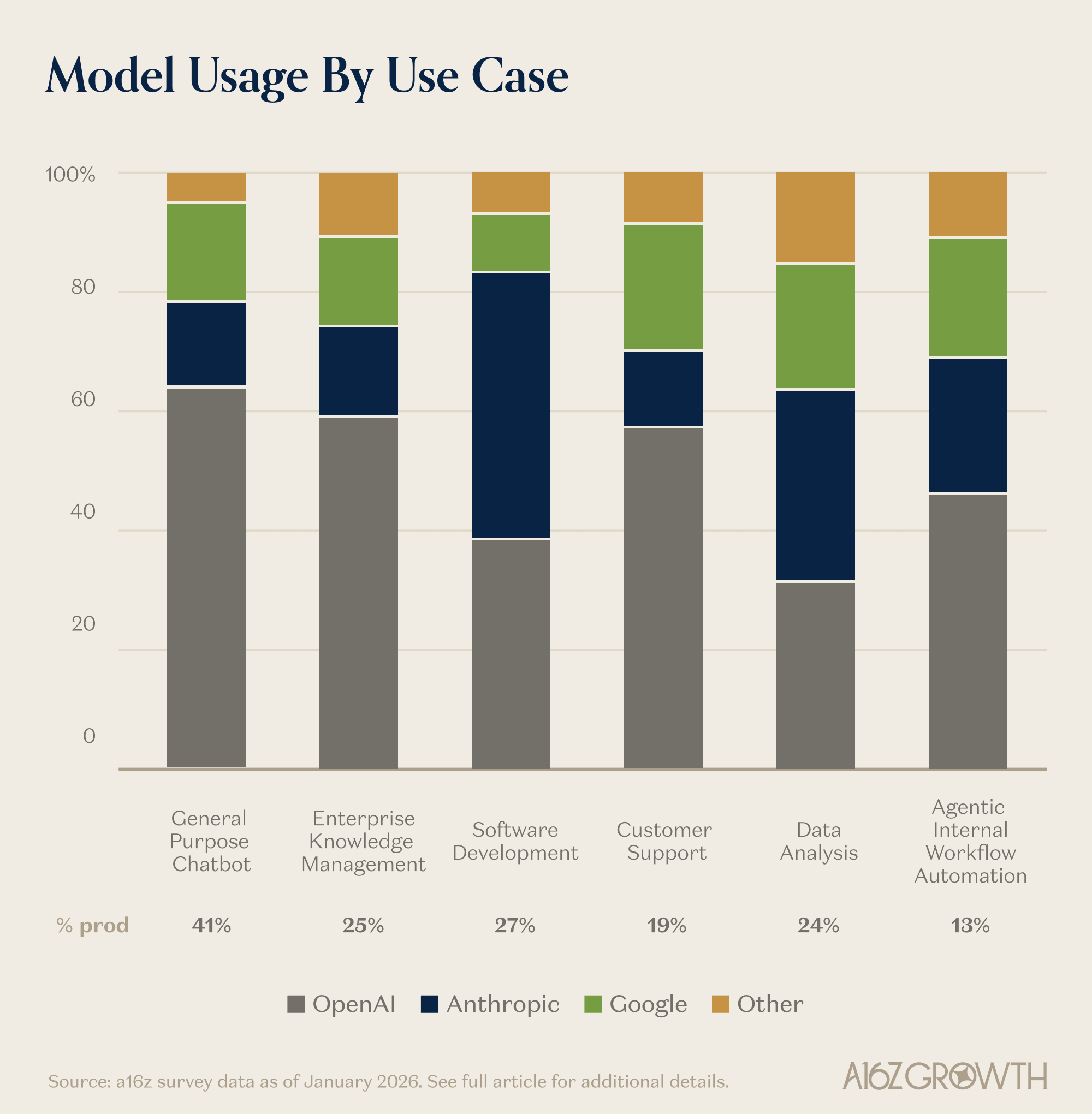
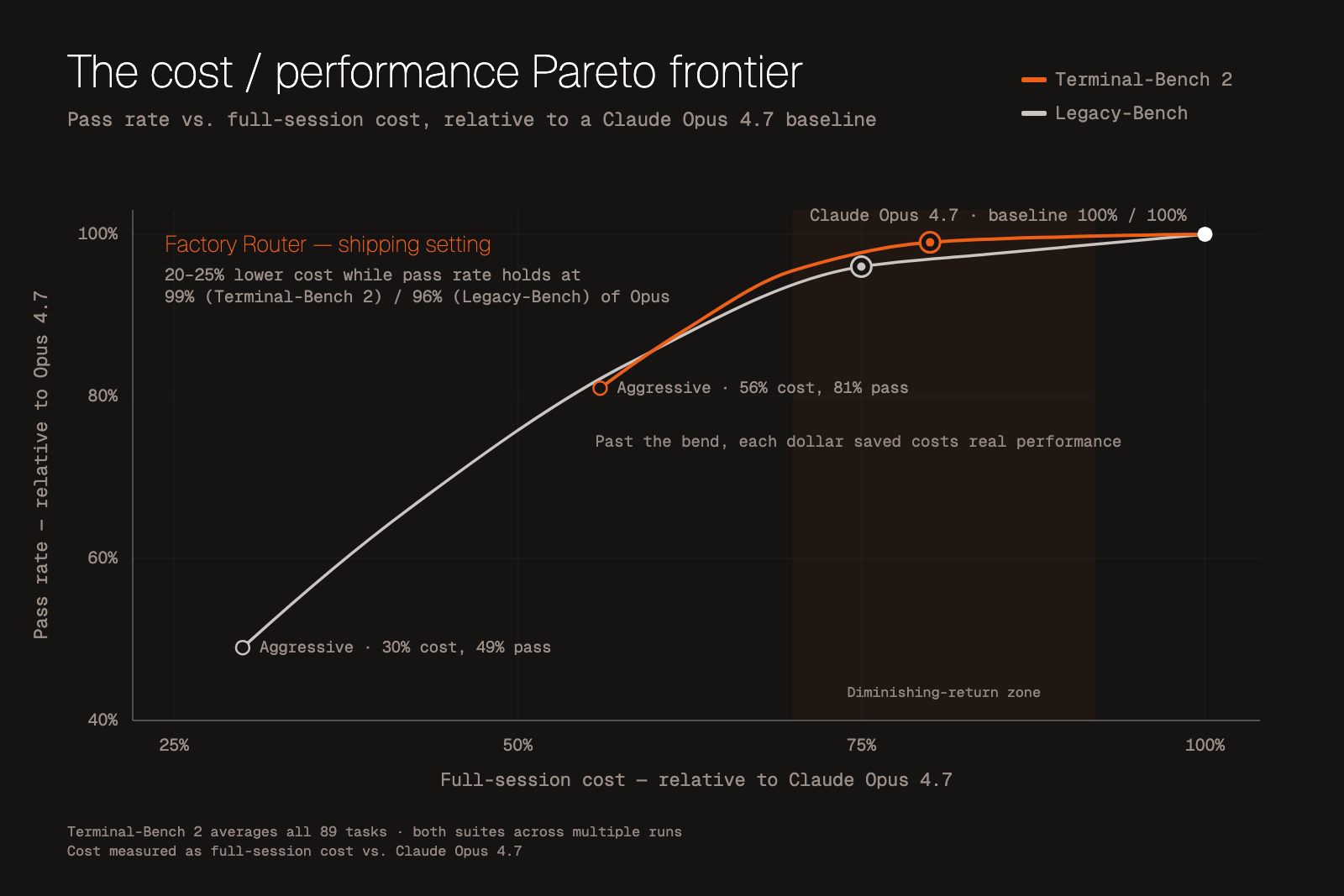
The Frontier Is Jagged
Routing works because the frontier is jagged. Factory says its router cuts token spend 20-25% while maintaining near-frontier engineering performance. That is the useful signal in the curve: some real work can move away from the premium model without much quality loss.
AI-native companies already behave this way. Sierra describes a "constellation of models" for customer agents. Decagon says its agents use OpenAI and Anthropic models by task. Ramp Labs tracks token spend across providers by person, team, project, model, and use case.
Benchmarks are also losing their sharp edges. A 2026 ICML paper on benchmark saturation found that nearly half of 60 language-model benchmarks were saturated. Web-Bench shows the coding version: HumanEval Pass@1 at 99.4% and MBPP at 94.2%. When the exam is saturated, the A+ stops being a buying signal. Ask which route completes your work for less.
Routing research fits the same world. Berkeley's RouteLLM showed large cost reductions versus always using GPT-4 while preserving most performance. RouterBench starts from the premise that no single LLM handles every task best when performance and cost both matter.
Developers are already acting this way. They switch between Claude, Codex, Gemini, OSS models, and IDE-native agents because quality moves by task and by week. Your company should turn that instinct into policy.
Let Your Experts Define Done
Build that policy inside the business before the vendor menu takes over. Most companies do this backward: buy the model, open access, watch usage spike, hunt for ROI after the invoice arrives.
Start with the work. For each recurring workflow, write the criteria for success before choosing a model or prompt.
Work with your experts. Support knows which resolution counts. Finance knows what makes a close narrative acceptable. Legal knows which redlines create risk. Engineering knows when a pull request is useful and when it is review debt.
Ask what failure looks like, which mistakes review catches, what can be automated, and what still needs a human. Then define the route: context, tools, output format, escalation threshold, model class, task budget, failure cost, and data boundary.
Tag every LLM call by use case: classifying, retrieving, drafting, executing, verifying, deciding. Without that tag, spend is just premium API flow.
Measure accepted work from your own operations. Benchmarks help with procurement. Your criteria decide what goes to production.
Run bakeoffs across frontier labs, mid-tier models, OSS routes, vertical products, deterministic code, and human review. Beat the current path on accepted output, review time, latency, security risk, and total cost.
Route from there: fast mid-tier models for latency, frontier models for judgment, deterministic code for rules, humans when failure is expensive.
Finance needs spend by use case. Security needs approved data routes. Operators need traces.
Set the Standard
The labs will keep shipping better models. Use them. Just do not let a vendor's upgrade path become your operating policy.
Tokens are costs. Benchmarks are signals. Model launches are supplier updates. Your work decides the route.
Beware of the lab incentive problem. The vendor wants more work to flow into premium usage. Your standard is stricter: the right model, tool, or human review path for the job, measured by accepted work per dollar.